

Advancing Multimodal Video Generation with Responsible AI and Stylization
13 Jan 2025
The research examines video generation, fairness, model scaling, super-resolution, and zero-shot evaluation, with a focus on Responsible AI and stylization.

Multimodal AI for High-Fidelity Video Creation and Editing
13 Jan 2025
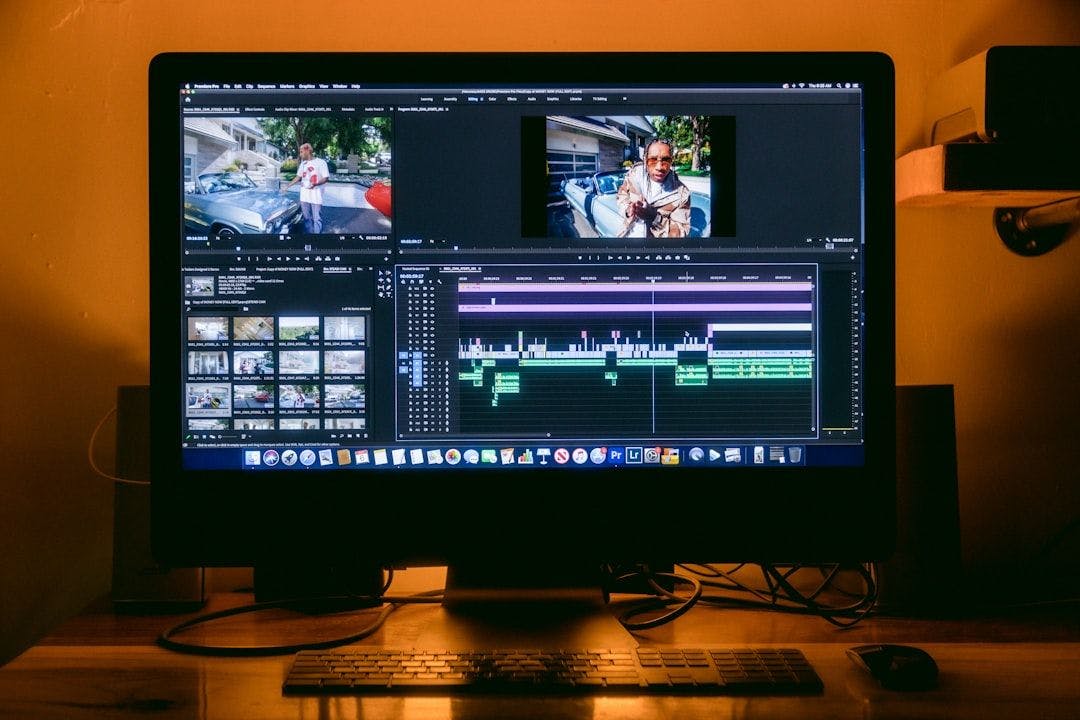
The research presents a multimodal model trained on visual, text, and audio tokens, excelling in high-fidelity motion, multi-task video creation, and editing.

Comparison with the State-of-the-Art
13 Jan 2025
The study compares VideoPoet to other models, scoring videos on text fidelity, quality, motion realism, consistency, and interest in side-by-side tests.

LLM’s Diverse Capabilities in Video Generation and Limitations
13 Jan 2025
The research article discusses LLM’s Diverse Capabilities in Video Generation and Limitations.

Pretraining Task Analysis On LLM Video Generati
12 Jan 2025
The research analyzes T2V, T2I, and SSL tasks (FP, Painting, AVCont) using 50M video/text-image subsets, with audio tasks sampled from videos with sound.
Experimental Setup For Large Language Model Video Generation
12 Jan 2025
The research examines 2T tokens, fine-tunes for text-to-video tasks, and evaluates zero-shot benchmarks including MSR-VTT, UCF-101, and Kinetics 600.
Task Prompt Design For LLM Video Generation
12 Jan 2025
VideoPoet uses task-specific prefixes with text, visual, and audio tokens, training only on outputs like visual and audio tokens with special task prompts.

Training Strategy For LLM Video Generation
12 Jan 2025
This research paper proposes using Alternating Gradient Descent for efficient multi-task training, minimizing padding by grouping tasks by sequence length.

Language Model Backbone and Super-Resolution
11 Jan 2025
Image, video, and audio are tokenized into a shared space, enabling a decoder-only model to generate outputs and control tasks via input-output token patterns.