

Authors:
(1) Prerak Gandhi, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai, [email protected], and these authors contributed equally to this work;
(2) Vishal Pramanik, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai, vishalpramanik,[email protected], and these authors contributed equally to this work;
(3) Pushpak Bhattacharyya, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai.
Table of Links
- Abstract and Intro
- Motivation
- Related Work
- Dataset
- Experiments and Evaluation
- Results and Analysis
- Conclusion and Future Work
- Limitations and References
- A. Appendix
4. Dataset
For movie plot generation, we have taken the plots from Wikipedia. The prompts for this task have been taken from IMDb. In IMDb, this prompt can be of two types. The first is a short description (15–40 words) of the movie, while the second is a long storyline, which varies from 30–200 words and contains much more details about the different characters and events of the movie. We have also collected the genres of each film from IMDb. We then divide the plots using a 4-act structure. For scene generation, we take the scripts from IMSDb and annotate them with the key elements of a scene.
4.1. Plot Generation Dataset
We have created a dataset of 1000 plots consisting of both Bollywood and Hollywood plots, extracted from Wikipedia using the wikipedia module in python. The plots collected are around 700 words long on average.
4.1.1. Annotation Guidelines
We annotate the plots by manually dividing them into 4 parts using the 4-act structure described in appendix A.5. We place a single tag at the end of each act: 〈one〉 (Act 1), 〈two-a〉 (Act 2 Part A), 〈two-b〉 (Act 2 Part B) and 〈three〉 (Act 3) as delimiters. An example for plot annotation is given in the appendix (Figure 6).
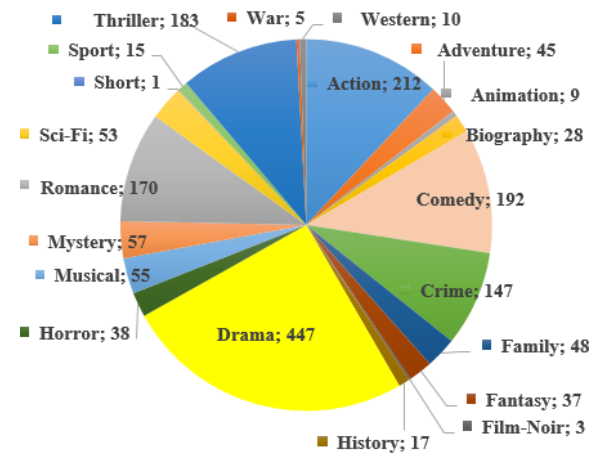
4.1.2. Movie Genres
To bring some controllability to the plots generated by the model, we have introduced the genres of the movies in the dataset along with the storyline. We concatenate the genres at the beginning of the storyline. Figure 2 shows the distributions of genres in the dataset.
4.2. Scene Generation Dataset
Movie scripts are very long. A 2-hour movie corresponds to around 30,000 words. Language models used for creative text generation, like GPT-2 and GPT-3, have token limits of 1024 and 2048, respectively, making it impossible to handle an entire script in one go. Hence, we divided the scripts into scenes and manually created their short descriptions. This allows training the scenes independently instead of relying on any previous scenes.
Movie scripts comprise of multiple elements described in appendix A.4. The different elements increase the difficulty models face in learning to distinguish each element. To overcome this obstacle, we tag four major elements throughout the script — sluglines, action lines, dialogues and character names.
4.2.1. Annotation Guidelines
We keep the four major elements present in every script — sluglines, action lines, character name and dialogues— and remove any other type of information such as page number, transitions or scene dates. The tagging of the four major elements is done using beginning and ending tags that are wrapped around the elements, as shown below:
• Sluglines: 〈bsl〉...〈esl〉
• Action Lines: 〈bal〉...〈eal〉
• Character Name: 〈bcn〉...〈ecn〉
• Dialogue:〈bd〉...〈ed〉

An example of an annotated scene is seen in Fig 3.
This paper is available on arxiv under CC 4.0 DEED license.